


Ако сте мрежов инженер, който за пръв път се сблъсква с Amazon Web Services, първото впечатление може да бъде доста объркващо, поради (маркетингово гениална, ашколсун!) употребата на традиционно позната терминология, като например рутинг таблица, рутер, интерфейс, и др., но представяща конструкции на различно ниво от това на традиционните мрежи.
Ако сте се занимавали с различни технологии за виртуализация на изчислителни мощности и/или мрежов транспорт, ще се изкусите да отъждествите това, което виждате с някоя от технологиите, които познавате, напр. изчислителната виртуализация с нещо като VmWare ESX, KVM, или друг хипервайзър, а виртуализацията на транспорта – с любимият ви овърлей, бил той NVGRE, VxLAN, VRF-Lite или нещо друго.
Това би било отчасти вярно, но само отчасти.
AWS, разбира се не предоставят абсолютно детайлна информация за това как точно материализират платформата си, но ако свържете личният си опит с мрежова виртуализация с опитът си с работа в AWS, малко „четене между редовете“ от различна публична информация, и достатъчно гледания на правилните re:Invent сесии, можете да си изградите сравнително добра представа за иновациите, които Амазон са предприели, как те са свързани помежду си, както и какво означава това за вас като мрежов архитект в различен контекст.
В настоящата публикация ще се опитам да обобщя собственото си разбиране за това как функционира AWS от мрежова гледна точка, основно от пещерата на личният опит и използвайки концепцията за т.нар. равнини на абстракция.
Ако не ви се чете – ето тук има линк към TLDR;
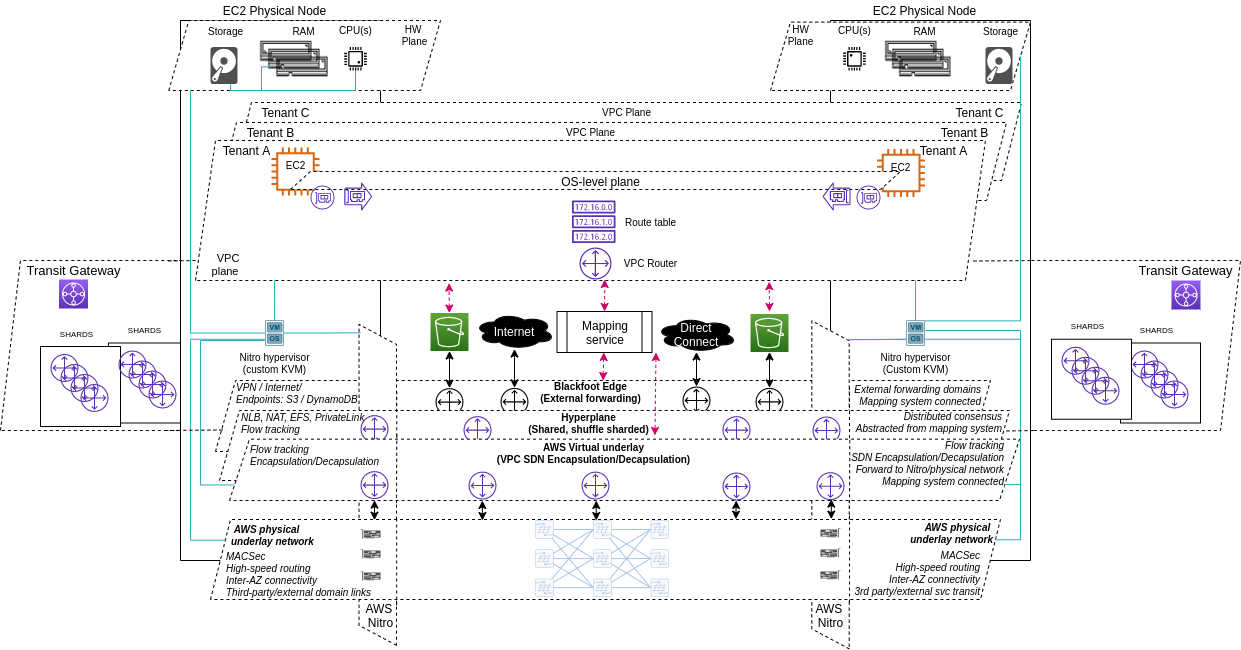
Равнини на абстракция
За себе си съм установил, че когато разглеждам комплексни системи, мисленето за тях като за различни равнини или нива на абстракция, ми помага да ги осмисля. Абстракцията представлява скриване на детайлите по вътрешната функционалност на някаква система, и заменянето им с концепции и функционалност от по-високо ниво, като в компютърните технологии това постига основно междуплатформеност, както и устойчива зависимост, надграждане. OSI моделът е абстракция (като повечето слоеви модели), всяко API – също. Тези API абстракции могат да бъдат на различни нива, в зависимост от тяхната функционалност и какво точно абстрахират, формирайки нещо като равнини на абстракция, със съответният набор от функционалност, която привидно съществува самодостатъчна, но на практика е свързана с по-комплексни системи по-надолу.
Във философията съществува метафизичният термин за т.нар. равнина на иманентност – поле, или равнина за създаване на самосъдържащи се концепции, без външен генезис или трансцендентност. Наслояването на абстракции върху абстракции върху абстракции, ведно с терминологичното скриване на функциите от по-долно ниво (използването на едни и същи термини на различни нива), създава една илюзия за самосъдържателност в наслоените ИТ системи, нещо като предполагаема равнина на иманентност – освен функционалност и проблематика, вече има експертност на точно определено ниво, без фокус върху връзките с по-ниски нива. Нещо подобно има предвид Кун в своята философия на науката, въвеждайки терминът „парадигма“ в научното развитие; с този термин, обаче, вече е злоупотребявано прекалено много, равнини на иманентност не би било напълно практически коректно, затова ще се придържам към „равнини на абстракция“.
В Amazon Web Service от гледна точка на комуникацията съществуват няколко такива равнини – ще ги спомена „отгоре надолу“, започвайки от най-близката до потребителя:
- Равнина на приложенията и операционната система: всякo VPC се състои от набор EC2 инстанции, всяка от които има операционна система, и/или други приложни механизми, които трябва да функционират така, сякаш ресурсът съществува в личният ви датацентър, или офис-среда. Същото се отнася и за serverless концепции, като ламбда, или за абстракции на приложно ниво, като контейнеризирани системи;
- Равнина на VPC – това е равнината на която функционират всички VPC конструкции – EC2, S3, RDS, ENIs, VPN Gateway, Transit Gateway, и т.н. – всички тези конструкции трябва да могат да комуникират една с друга, чрез конструкции от същото ниво, като същевременно са използваеми от равнината на приложенията и операционната система, без да разкриват функционалността на равнините от по-ниско ниво, на които текущата равнина разчита (с други думи, VPC router услугата и т.нар. рутинг таблица трябва да предоставят същата функционалност на VPC равнината, без да разкриват как тази функционалност се транслира във физическа мрежова свързаност). Разбира се, всеки клиент е отделен от останалите, но неговите VPC-конструкции са на същото ниво на абстракция;
- Равнина на изчислителна виртуализация и storage – след като все пак си говорим за виртуализирани машини, самата изчислителна виртуализация трябва да се случва по някакъв начин – по традиция един или друг хипервайзър отговаря за тази функционалност, и това не се променя принципно в AWS; Това, което се променя са нюансите на имплементацията на хипервайзъра.
- Равнина на свързаност към трети страни и услуги – това е една от иновациите на AWSвключва абстракция на свързаността към външни за AWS среди – VPN-и, директна свързаност към клиенти, Интернет-свързаност, и т.н. Интересното тук е, че функционалността на тази равнина е свързана с функционалността на VPC равнината, като доставчик на услуга;
- Хипер-равнина – тук се случват всички flow-базирани операции, извикани от VPC -равнината – мрежов лоуд балансинг, NAT, transit gateway, и др.,;
- Равнина на виртуалната мрежа, или овърлей – тук имам предвид не точно функция по по транспорт на данни, а по енкапсулиране на данните/пакетите, идващи от VPC-равнината, респ. операционната система, в хедъри, информирани от VPC-равнината, т.е. включващи идентификатори от тази равнина, съответно даващи възможност за декапсулация и транслация между равнините;
- Физически субстрат – тук са традиционните концепции като мрежови карти, физически суичове и рутери, и пр.
Изчислителна виртуализация и storage
Гледайки на нещата от мрежова гледна точка, няма да се занимаваме прекалено много с изчислителният хардуер , въпреки че и там има предостатъчно иновация – custom чипове, мрежови карти, и пр. Както знаем, основният продукт на AWS е т.нар. Elastic Compute, или EC2, което е една или друга форма на виртуални машини. По отношение на виртуализацията, Амазон използва custom KVM хипервайзър, заменяйки предишният Xen такъв. Основната идея на custom-изацията е да изтъни максимално функционалността на хипервайзъра, като той се занимава изключително с виртуализация на достъпа до процесор, памет, и storage. Разбира се, различните добавени функции като мрежова виртуализация, сигурност, крипто, и т.н. не са ненужни, но пък могат да бъдат отделени в самостоятелен хардуер.
На всеки физически сървър работи един виртуален рутер, който има за задача да приема данни от по-високо ниво на абстракция (VPC равнината вероятнo) и да ги енкапсулира така, че да минат през различни мрежови възли, за да стигнат до крайният си получател – физически сървър, и виртуална машина във VPC контекст. Тези нодове изглежда могат да бъдат освен физически, също така и виртуални, т.е. други EC2 инстанции, но такива използвани от Амазон на по-ниско ниво, а не стартирани от потребители. (Амазон нарича това хипер-равнина).
Самата енкапсулация и декапсулация на данните във VPC-осъзнати хедъри и IP датаграми, се случва от Nitro мрежовите карти и/или виртуалните рутери на физическите сървъри (в зависимост от вида хардуер, на който работи виртуалната EC2 инстанция – повечето нови типове EC2 инстанции работят върху т.нар. Nitro хардуер, т.е. това се случва в мрежовата карта, която е вътрешна разработка на Амазон.
VPC и multitenancy
Първата равнина на абстракция, разположена най-близко до потребителя, е VPC-то. Всяко VPC се простира върху различни физически сървъри, които разбира се се свързани с физическа мрежа. Естествено, физическата мрежа не е достъпна, нито видима за консуматора на VPC-тата, но дори виртуалната софтуерно дефинирана мрежа е скрита от него. Виртуалните машини, които работят във VPCто, имат виртуални мрежови интерфейси, но те са „преносими“, или независими компоненти, които са независими от изчислителната инстанция. Как се прави това не е напълно ясно, но един начин да направите нещо подобно, както например прави OpenStack, е с изпозлване на transparent бриджове и тунели (също тук). Преносимостта на този интерфейс е въпрос на автоматизация на конфигурацията върху друга инстанция, в случай на „преместване“. За да скрием тази функционалност още повече, можем например да вкараме тази конфигурация в драйвер за виртуалната мрежова карта на клиентската инстанция (тук спекулирам, но виртуалните еластични мрежови интерфейси в AWS се материализират като мрежов интерфейс в операционната система на всяка една инстанция).
От гледна точка на функционалност, всичко това е нормално – всяка мрежова виртуализация крие физическата мрежа от консуматора, чрез една или друга енкапсулация. Интересното тук е иновацията на скриване на SDN компонента.
Всяко VPC включва рутер, като на практика това е разпределена, децентрализирана услуга от множество рутиращи равнини. VPC-то може да създава маршрути в неговият „VPC рутер“ , но за разлика от нормалните рутери, next hop-а за всеки маршрут в този рутер не е IP адрес – нито от нивото на VPC-то, нито от по-ниско ниво на енкапсулация, а е друг обект от VPC равнината: Elastic Network Interface, или друга AWS услуга, инстанциирана в същото VPC – Internet gateway услуга, VPN gateway услуга, Transit gateway услуга, и др. адресирани като нод или обект, чрез техният обектен или service identifier, а не чрез специфичен мрежов адрес. Това означава, че не просто физическата мрежа, а самият SDN овърлей е скрит от VPC равнината, т.е. всеки път, когато разпределената рутер услуга трябва да рутира пакет от EC2 инстанция до друга EC2 инстанция или някоя VPC услуга, нещо трябва да „преведе“ обектният идентификатор на следващият хоп в „маршрутната“ таблица която съществува във VPC равнината, до фактически адрес от едно или друго субстратно мрежово ниво, преди в крайна сметка въпросният пакет да бъде изпратен до физическият сървър, където се намира EC2-интанцията-получател, където данните да се качат отново на равнината на VPC и EC2 инстанцията. ENI-идентификатора на EC2-инстанцията изпращач, трябва да се отъждестви с физическият сървър, върху който тя работи, който пък да енкапсулира пакета в подходяща енкапсулация, преди да изпрати данните по физическата мрежа (това е принципна функция на хипервайзъра, но AWS и техният Nitro хипервайзър я разпределя между хипервайзъра и Nitro мрежовата карта); Адресът на получателя, трябва да се отъждестви с ENI-идентификатор, който пък да се отъждестви с физическият сървър, където върви EC2-инстанцията получател, за да може пакетът да бъде доставен до нея; това трябва да се случва във VPC-изолиран контекст, т.е. физическата мрежа не трябва да знае кое VPC комуникира с кое друго VPC, нито VPC-то да знае как точно данните се движат във физическата мрежа. Освен това, целият този „превод“ трябва да се извършва в секюрити контекста на акаунта-собственик на инстанцията-изпращач на данните и акаунта-собственик на инстанцията-получател на данните. Тези два акаунта не е задължително да са едни и същи, въпреки че инстанциите могат да са в едно и също VPC.
Всичко това прави т.нар. „рутинг таблица“ във VPC-равнината еквивалентна по-скоро на „policy routing“ концепцията в традиционните мрежи – конструкция от правила, казващи на някакво underlying оборудване (физическо или виртуално) как да forward-ва определени пакети.
Традиционно връзките между различните равнини на абстракция в един протокол за мрежова виртуализация са уредени от протоколната имплементация в мрежовия нод – ако ползвате vxlan или nvgre, или omp, или други овърлей енкапсулации, всеки мрежов възел (суич, рутер, и т.н.), участващ в овърлея има възможност да енкапсулира или декапсулира хедърите на въпросният овърлей, и така да пропуска данни до по-ниската равнина, когато е необходимо. Амазон обаче използват собствена енкапсулация, с VPC осъзнатост, защото са преценили, че никой от овърлей протоколите, достъпни на пазара към момента, не е достатъчно ефективен в мащаба, в който тяхната инфраструктура изисква. (Линк)
Услугата, която прави възможни всички тези отъждествявания между обекти от различните равнини на абстракция, се нарича mapping service, или свързочна услуга.
„Физически“ субстрат
Физическата мрежа, върху която върви Amazon Web Services е напълно абстрахирана от потребителите на VPC ниво и ниво услуги. От различни места (тук, тук) знаем, че компанията разработва собствени мрежови карти, под шапката на Nitro бранда, който също така включва модифицираният KVM-базиран хипервайзър, секюрити чип контролиращ фърмуер-ъпдейтите, и други компоненти. Тази мрежова карта е натоварена с доста функции, които иначе биха били задача на процесора – stateful аксес-листи, които AWS нарича security groups, извършва енкапсулация и декапсулация на данните в хедъри на custom-разработеният, VPC-aware, овърлей протокол, използван от амазонската „software-defined“ мрежа, рутиране, и хардуерна акселерация.
Друго интересно нещо, което се знае за физическата мрежа на Амазон е това, че разработват собствени мрежови устройства, предпочитат да използват 25-гигабитов Ethernet, и да комбинират не прекалено големи дата центрове в т.нар. „мрежови региони“. (Източник)
Виртуален субстрат и/или хипер-равнина
AWS платформата използва собствените си услуги – това е една от често срещаните маркетингови опорни точки на Амазон и тя вероятно ви звучи чудесно, освен ако не сте Насим Талеб. Transit Gateway използва S3 за съхранение на правилата, които въвеждате в неговите „рутинг таблици“. Хипер-равнината и/или виртуалният мрежов субстрат, стоящ между физическата мрежа и по-горните равнини (казвам и/или, защото не съм сигурен до колко двете са консолидирани, но при всички положеният са тясно зависими една от друга), е вътрешна услуга, която се използва от Private Link (която самите AWS използват за т.нар. private interface endpoints), NAT, EFS, Load Balancing, Transit Gateway, а вероятно и други услуги, които AWS предоставя на клиенти. Както вероятно става ясно, всяка от тези услуги е свързана с поддържането на flow-базиран state: всяко nat-нато flow има вътрешен адрес, source и destination port, които се отъждествяват освен с външен адрес, също и с външен source и destination порт. Хипер-равнината се състои оt комуникационни EC2 нодове, които избират кой точно traffic forwarding нод да обработи определен flow. Oсвен че си предават трафик, за да извършват тази координация, те трябва да поддържат синхронизиран, разпределен консенсус за състоянието на потоците, които насочват към различните forwarding нодове. Проблемът с поддържането на този консенсус е сложен сам по себе си, не знам как точно Амазон го решават, но освен на хипер-равнината, той съществува и е решен също при техният mapping service.
Интересното тук е, че поддържането на този state изисква нодове, които да го правят, които от своя страна имат свойството да fail-ват. Тук идват размисли за high-availability, redundancy, и ефектът от fail-ването на системи, и иновацията на Амазон в този план е ефективен механизъм за ограничаване на failure бласт радиус-а, наречен „shuffle sharding“ – мапване на клиентската услуга (в случая, трафик/flows, но самият механизъм идва от тяхната DNS услуга, Route53 и принципно може да се използва в различни измерения) от случайно подбрани клиенти, с някаква степен на припокриване, към redundant групи от нодове, т.е. вместо просто група от нодове, shard-а е редифиниран като tuplet от клиент+група нодове. Групите от нодове, към които случайно се мапват групи от клиентски услуги, могат да се състоят от различен брой нодове, поне 4, а припокриването на различните клиенски потоци в шардовете също може да варира.
Още един хубав линк за хипер-равнината.
Равнина за свързаност към трети страни и услуги (Blackfoot)
Южноафриканският пингвин Blackfoot, дава своето име освен на една от сградите на AWS в Сиатъл, също и на вътрешната услуга, предоставяща свързаност към трети страни. Така, както хиперравнината е съставена от EC2 нодове, които поддържат децентрализиран flow state, Blackfoot e съставена от мрежови нодове, които правят протоколна транслация между енкапсулациите на VPC равнината, и други протоколи, свързващи тази равнина с трети страни. Това може да е IPv/6 за директна Интернет свързаност, IPSec енкапсулация за VPN към фирмени мрежи посредством потребителската услуга VPNGW, Layer3/2 протоколи използвани при Direct Connect, и др.
Свързочна услуга (mapping service)
Както вече споменахме, mapping service е услугата, предоставяща разпределено, децентрализирано отъждествяване между компоненти от VPC-равнината и равнини на абстракция от по-ниско ниво. Както можем да си представим, ако IP адрес от VPC равнината трябва да се отъждестви с IP адрес, или физически сървър, където EC2 инстанцията-източник на трафика се намира, преди пакетите да бъдат изпратени по физическата мрежа, добре е това отъждествяване да се случва възможно най-бързо. Ако за всеки такъв пакет трябва да се прави запитване към мапинг сървиса, това би направило времезабавянето на операцията непоносима, а високата мрежова производителност – невъзможна. Затова, Амазон по същество трансформират този проблем в разпределена, децентрализирана база данни: всички мапинги между елементи от една равнина и съответните им елементи от по-ниска равнина, се популират и разпределят в локални кешове на всеки физически сървър, където вървят EC2 инстанции. Това прави запитването към мапинг сървис-а много по-бързо, самият кеш се осъвременява при ъпдейти, а от Амазон твърдят, че дори не са имплементирали cache_miss операцията, т.е. единственият начин пакет да премине през енкапсулацията от по-високо към по-ниско ниво и в крайна сметка да бъде изпратен по физическата мрежа, е чрез мапинг сървис кеша. (Линк)
Разбира се, връзките между виртуални адреси на EC2 инстанции и физически адреси на хост-сървъри не са единствените мапинги които свързочната услуга предоставя: ако една инстанция трябва да изпрати пакет до услугата по връзка с трети страни, мапинг услугата трябва да отъждестви обектът от VPC равнината (например обектният поименен идентификатор на VPN Gateway услуга, както е записан във VPC „рутинг таблицата“) към обект от Blackfoot равнината, съдържаща устройства/инстанции за свързаност с трети страни. Ако пакетът е предназначен за мрежов лоуд балансър, това е конструкция от хипер-равнината, и мапинг сървиса трябва да може да отъждестви тези обекти с фактичесткото им физическо местоположение.
Всичко това се случва само чрез локалния мапинг сървис кеш, без cache_miss-ове. Би било изключително интересно да разберем как тази система се реализира на практика.
Равнина на операционна система и/или приложения
Това е равнината, в която работят всички приложни системи – операционните системи на EC2 инстанциите, контейнеризирани системи като kubernetes, ламбда, и др. Много мрежови вендори поддържат собствени Marketplace image-и на виртуализирани платформи, които могат да се стартират в AWS – Cisco CSR1000v, Arista vEOS, Palo Alto VM-Series, F5 BIG-IP VE, и др. Това дава възможност да използвате вече познат feature-set, и да изграждате VPC-мрежи на OS-ниво, като използвате VPC-равнината като underlay. Това, разбира се, си има своите недостатъци – трябва да се грижите за всичко, за което се грижите в собствената си виртуализирана среда – конфигурация, redundancy, лицензи, скалируемост, и т.н. – все проблеми, които не би трябвало да имате (поне не в същия мащаб), ако се престрашите да предоставите контрола върху traffic forwarding на Амазон, използвайки техните услуги, за функционалността на които нямате видимост или контрол, освен scoped API-тата, с които тези услуги се инстанциират и/или конфигурират донякъде.
Прост пример за това е комуникацията между две EC2 инстанции в едно (или в различно) VPC: можете да кажете, че EC2-инстанция 1 ще използва локалният гейтуей за VPC събнета, в който се намира, с което казвате, че целият трафик, който излиза от инстанцията е видим за хипервайзъра и Амазонският SDN, без да имате контрол или видимост върху него – ARP бродкастите ви за локалният гейтуей се прихващат от хипервайзъра, енкапсулират се в VPC-aware хедъри, мапинг сървис кеша казва на кой физически сървър се намира инстанцията получател, проверява се IAM и секюрити контекста на изпращача и получателя, хипервайзъра връща на инстанцията ARP-отговор, трафикът минава през избраният traffic forwarding node, държащ гейтуей IP-то (много вероятно anycast-нато), и продължава, рутиран на underlay ниво, до инстанцията получател. Всичко това се случва прозрачно за вас. Другият вариант е, ако не искате VPC forwarding услугата да има пълен контрол върху трафика между самите инстанции, да си изградите OS-level тунел между инстанциите, симулирайки директна свързаност. Това се прави често с различни транзитни инстанции, особено при хибридни миграции, където приложенията все още имат зависимости от вътрешни/on-prem инфраструктури и/или потребители, мрежовият и секюрити контекст не е напълно изчистен, и/или различните екипи, отговорни за различни функции не са на едно и също skillset-ниво що се касае до клауд компетенции. Така си запазвате поне една част от контрола върху трафика (същото, което прави Амазон), комбинирайки я с механизъм за телеметрия на базата на виртуалният OS-level интерфейс, като все пак използвате разпределената forwarding услуга на Амазон, но тя вижда само енкапсулиран трафик. Това ви дава предимството да използвате съществуващи процеси и екипи за поддръжка на транзита между инстанциите, от който зависят приложенията ви, но цената на това е, че току-що сте качили на най-високата равнина на абстракция всички проблеми от по-ниските равнини – рутиране, redundancy, скалируемост, и т.н. с всички свързани с това недостатъци (MTU/MSS проблеми, да речем).
Истината вероятно е някъде по средата – започвайки от нивото, което ви дава възможност да се придвижите напред, осъзнавайки ограниченията на това ниво, и изчиствайки процесно/архитектурно/секюрити контекстът на проекта, можете да еволюирате по-нататък.
Транзитна услуга (Transit gateway)
Transit Gateway услугата по същество разширява функционалността на рутера от VPC равнината до комуникации между различни VPC-та. Ако мрежовите интерфейси (ENIs) могат да бъдат идентификатори за next-hops в децентрализираната рутираща услуга, която дава възможност на EC2 инстанциите в едно VPC да комуникират помежду си, и имайки предвид че VPC е чисто логическа конструкция, то тази абстракция може да бъде разширена и за комуникация между EC2 инстанции от различни VPC-та. Разбира се, в случая на комуникация между инстанции от различни VPCта, са необходими няколко неща:
- интерфейс към рутиращата услуга: рутиращата услуга от всяко от VPC-тата трябва да знае към кой „target“ ENI да праща данни, които да бъдат изпращани между VPCта. Това не може да е една единствена инстанция, а да бъде още един managed service, следователно трябва да имаме специален вид мрежови интерфейси, които са интерфейси към тази услуга. Тези интерфейси са т.н. Transit Gateway Attachment интерфейси – обикновено те се инстанциират във всеки availability zone на VPCто и се групират под общ Transit Gateway Attachment ID за всяко VPC. Така се пресъздава на по-високо ниво концепцията за виртуални дата центрове, свързани помежду си, и се дава възможност за логически топологии на базата на VPC-към-VPC комуникации.
- логически топологии на видимост между нодовете – услугата, която ще дава възможност на инстанции от различни VPC-та да обменят данни, трябва да поддържа възможност за различни логически топологии, т.е. да има форма на ограничение и/или предвидимост на видимостта между различните VPC-та. В традиционните мрежи това се случва на базата на forwarding таблици от различни нива, които се изграждат или динамично от протоколи, обменящи си адресна информация от различни слоеве (това може да са адресни идентификатори напр. от IPv6, IPv4, MPLS LSP етикети, IPX) или статично чрез конфигурация на съответствия между локално значими идентификатори (frame relay DLCI, ATM VPI/VCIs и др.). Допълнително, когато е необходимо да се настрои самата комутация и данните да минат от едно ниво на енкапсулация на друго, трябва да има механизми за изграждане на съответствия и евентуално дистрибуция на тези съответствия между участващите нодове (тази функционалност се добавя от ARP за IP/Ethernet, в IPX тя не е необходима защото е вградена в нод адреса, Frame relay и АТМ използват inverse ARP, а за хората без сив цвят в косите – BGP NLRI разширенията, ползвани от eVPN например, позволяват да се обменят съответствия между VTEP адреси и VXLAN VNIs, както и IP:MAC съотстветствия свързани с тях). В случаят с Transit Gateway услугата – настройката на комутацията и съответствието между адресите от различните равнини е обфускирано от самата услуга, потребителят не го вижда и няма никакъв контрол върху него – за потребителят остава единствено настройката на видимостта чрез т.нар. transit gateway route tables. На пръв поглед тези рутинг таблици изглеждат подобни на VRF таблици, но също както във VPC равнината, това не са традиционни рутинг таблици (в рутинг таблиците имаме само дестинации – достъпващият ресурсите е по подразбиране локалното устройство, тук в таблицата присъства и достъпващият, както и достъпваният ресурс), а по-скоро набор от правила, установяващи кои VPC-та (идентифицирани чрез адресният идентификатор на своят TGW Attachment ID), могат да достъпват, или „виждат“ кои други VPC-та. Контролът върху достъпващият и достъпваният ресурс (VPC) чрез TGW рутинг таблиците се осъществява чрез т.нар. асоциация и пропагация – всяко VPC, чиито attachment е „асоцииран“ към дадена таблица, може да търси друго VPC, а всяко VPC, чиито attachment e „пропагиран“ в тази таблица, може да бъде намиран от VPC-тата, които са асоциирани. Това означава, че можем да имаме сравнителна гъвкавост по отношение на това кой може да праща данни на кого, създавайки различни логически топологии на свързаност. По подразбиране всички VPCта са асоциирани и пропагирани в една таблица по подразбиране и всеки може директно да вижда всеки друг, но ако искаме да реализираме логическа свързаност от тип „hub-and-spoke“, например, можем да асоциираме всяко spoke VPC в една „spoke-view“ таблица, където сме пропагирали нашето hub VPC, и да асоциираме само hub VPC-то в една „hub-view“ таблица, където сме пропагирали всички spoke VPC-та. Важно е да отбележим, че тези „рутинг таблици“ са чиста control plane функционалност – т.е. нямате никакъв поглед върху това кой и как фактически предава вашите данни по мрежата на базата на тези правила, дали те са отделени в отделен forwarding сегмент или не, и дали се групират с данни на други клиенти. Всъщност, понеже transit gateway услугата използва hyperplane нодовете споменати по-горе, можем да предположим че данните за flow state на различни клиенти се групират в различни shuffled shards. Традиционните рутинг таблици също са control plane функционалност, но там достъпващият таблицата винаги е локалното устройство, което вие контролирате, а не е децентрализиран и скрит зад абстракция. Не е ясно и къде се складират правилата за видимост между VPC-тата, формиращи „рутинг таблиците“, но можем да предположим, че това е друг AWS ресурс – или специални S3 bucket-и за транзит гейтуей, или в някоя от nosql услугите, които AWS предлага.
Малко размисли
Иновациите в AWS започват на съвсем фундаментални нива – от собствен мрежов интерфейс и системен хардуер, собствени чипове, собствени протоколни енкапсулации, собствен SDN control plane, собствен механизъм за децентрализиран state-keeping, през собствена хипервайзър разработка/модификация и собствени архитектурни методологии, до собствени дефиниции на термини, използвани години наред в традиционните инфраструктури за де факто собствен/гениален маркетинг.
Това оформя една самосъдържаща се, самодостатъчна вселена на технологично битие, консумацията на която е предоставвена на клиенти в брутално деконструиран вид: можете да използвате AWS, за да изградите алтернатива на собственият си дата център при тях, но можете и да ги изпозлвате, за да си пуснете едно единствено serverless приложение. Тази деконструкция става възможна благодарение на стандартизираният подход на взаимодействие между различните клиентски и вътрешни услуги, реализиран чрез API интерфейси, върху обикновен публичен HTTPS и достатъчно добре имплементирана криптография. Това означава, че ако услугите, които използвате, имат нужда да комуникират помежду си, вие няма нужда да разбирате как детайлно се случва това, въпреки че в някои случаи, особено напоследък, ви се предоставят някакви интерфейси за опосредствен контрол върху тези взаимодействия. Например, при използване на EKS managed service услугата (без Fargate), получавате възможност за изграждане на частни K8S клъстери, ако искате в рамките на едно единствено VPC, но пък с control plane API endpoint, който по подразбиране е публично видим, и който можете да направите частен (ако знаете как да си осигурите съответната свързаност към него след това).
Ще платите винаги точно това, което използвате, точно толкова, колкото го използвате, но ако искате да планирате цената на присъствието си в AWS, трябва да имате точно толкова гранулярен reporting за употребата на еквивалентните услуги в собствената си ИТ среда, а това е long-shot дори за много много големи корпорации.
Резултатът от всичко това е един фаустовски trade-off между lock-in и достъп до иновации – разчитате на ценовата обосновка на доставчика, която е обвързана с методите и инструментите на доставчика, а същият доставчик разбира се е този, където мигрирате вашето вътрешно ИТ – системи, данни, код, мрежи, дори свързаност с други вендори. Затова, когато става въпрос за мащаби по-големи от тези на един стартъп, цената не е единственият фактор, който да се взима предвид при оценка на миграции към AWS – ще получите възможност за изключителна гъвкавост и достъп до иновативен инструментариум, ако имате как да го използвате, но на цената на ограничена прозрачност и опосредствено потребление и контрол. Малко неща в AWS са такива, каквито изглеждат, дори и да имат познати имена – рутинг таблиците са по-скоро policy route конструкции, мрежовите интерфейси не са точно каквито ги познавате, Route53 не е точно DNS, и т.н. Нямате никакъв поглед или влияние върху това как интерфейсите, с които вие консумирате managed ИТ услугите, които ви се предоставят, всъщност си взаимодействат с вътрешната инфраструктура на доставчика, какви са вътрешните инфраструктурни зависимости (напр. знаем че много услуги ползват S3, някои критични вътрешни услуги ползват EC2, но не знаем точно как), choke points, и др.
Следователно, ако се занимавате с risk management, би трябвало да разглеждате самото си присъствие в AWS като експозиция, която да контролирате и балансирате – дали с вътрешна инфраструктура, дали с други public cloud доставчици, дали и с двете. Последното е свързано с доста ангажименти само по себе си – за да постигнете мащаб трябва да ползвате само услуги, които са достъпни във всички ваши public cloud vendor-и и трябва добре да помислите как ще оркестрирате работата с всички тези не задължително съвместими API интерфейси към конкуриращи се една друга услуги.
Въпреки всичко това, от инженерна/техническа гледна точка, public cloud пространството вече е достатъчно зряло, за да е обект на легитимен интерес и развойна дейност. Ако сте достатъчно възрастен и/или с достатъчно професионален опит извън тази сфера, вероятно ще ви се наложи да преминете през ваша собствена версия на „седемте етапа на скърбенето“ по „legacy“ IT и отворените стандарти, но след това ще имате възможност за съвсем еквивалентно и удовлетворително професионално развитие. 😉